
Tensordyne is making AI more efficient using logarithms.
But is compute efficiency the thing that matters?

Most AI chip companies are focusing on speeding up generative AI workloads by changing the memory hierarchy. Groq achieved ultra-low-latency at a high cost by using super-fast but expensive SRAM memory, rather than the slower but more cost-effective high-bandwidth memory (HBM) that Nvidia relies on. Cerebras is using wafer-scale processing to take that idea even further, with each wafer providing 44GB of SRAM. d-Matrix is leveraging processing-in-memory to improve performance by reducing data movement to and from memory. Taalas is using read-only memory, which is even faster and cheaper than SRAM, but can’t be changed -- so each chip can only run one model.
Tensordyne is approaching AI chips differently. They’re using a different kind of number system based on logarithms that allows them to multiply numbers more efficiently than chips using conventional floating point math. But translating more efficient multipliers into better performance on real AI workloads is hard. Today on the blog, we’re looking at Tensordyne’s unique technology, how it positions their chips relative to others in the market, and trying to answer the question: do more efficient compute engines actually matter for AI chips?
Logarithmic multiplication
The core technical advantage of Tensordyne’s architecture comes from its logarithmic number format. Instead of storing a value A as just A, they actually store log2(A). Then, if they want to multiply A by another value, B, they can use the logarithm product rule to perform multiplication using addition:
log2(A x B) = log2(A) + log2(B)
This idea isn’t new, but nobody has successfully used it in a commercial AI accelerator before. Running large matrix multiplications requires a lot of multipliers, but it also requires a lot of adders. The log product rule makes multiplication easier, but it makes addition much harder. Tensordyne gets around this using an approximation:
log2(1+x) = x for 0<x<1
But this approximation isn’t enough by itself. Originally, Tensordyne used quantization-aware training to get models running despite this approximation, but convincing customers to re-train models just for Tensordyne chips would be a huge challenge. So they figured out a set of additional proprietary tricks to make their approximation accurate enough for large models.
Tensordyne’s software stack converts PyTorch models to run with their specific number format. I’m a bit skeptical about whether they can do this without meaningful accuracy degradation, but even if they can, this conversion process raises another issue. Modern optimized inference pipelines aren’t just written in PyTorch; they have custom kernels optimized for GPUs and their specific numeric quirks. If a customer wants to port that to a chip with a whole new number format, it’ll take a lot of work to match the level of performance of optimized GPU kernels. Tensordyne claims that they’ll have AI agents help customers convert their code to Tensordyne’s software and numerical format… which seems like a bit of a cop-out answer. Fundamentally, writing kernels is hard, and to reap the (very real) benefits of Tensordyne’s chips, customers may need to bite the bullet and port kernels to Tensordyne’s logarithmic number format.
This specialized number format also makes it much, much harder for Tensordyne to support training workloads. Inference workloads are relatively forgiving to numerical changes like quantization, but training workloads have major numerical stability concerns. Training pipelines are specifically designed around hardware quirks, and can cost hundreds of millions of dollars to run. It just doesn’t make sense to build a new training pipeline for Tensordyne’s chips for a workload like training, which is primarily dominated by networking and memory bandwidth anyways.
Speaking of memory bandwidth… while Tensordyne is touting their new number system, most AI chips are focused on achieving breakthrough performance using new memory hierarchies. Is Tensordyne focusing on the wrong bottleneck for generative AI workloads?
Does more efficient compute matter?
There’s a reason why most AI chips have focused on innovating on the memory hierarchy, rather than fundamentally changing how the compute works: a lot of generative AI workloads are memory bound. If you want to use a single GPU to process a single LLM query, that GPU needs to load and unload all of the weights of every layer in the LLM to process that query. Even if you make the GPU much more efficient at matrix multiplication, you’re bottlenecked by the memory bandwidth.
GPUs get around this issue through batch processing. Instead of processing a single query at a time, they process a batch of multiple queries. If a batch has 32 queries in it, the GPU performs 32 sets of matrix multiplications for each layer it loads. This makes the workload less bottlenecked by memory bandwidth, and makes the efficiency of your compute engines actually matter. This can be modeled using something called the “roofline model”. As we increase the batch size, the arithmetic intensity of the workload increases -- in essence, it does more math per byte of memory transferred. The higher the arithmetic intensity, the more the efficiency of the compute engines matters. The lower the arithmetic intensity, the more memory bandwidth matters.
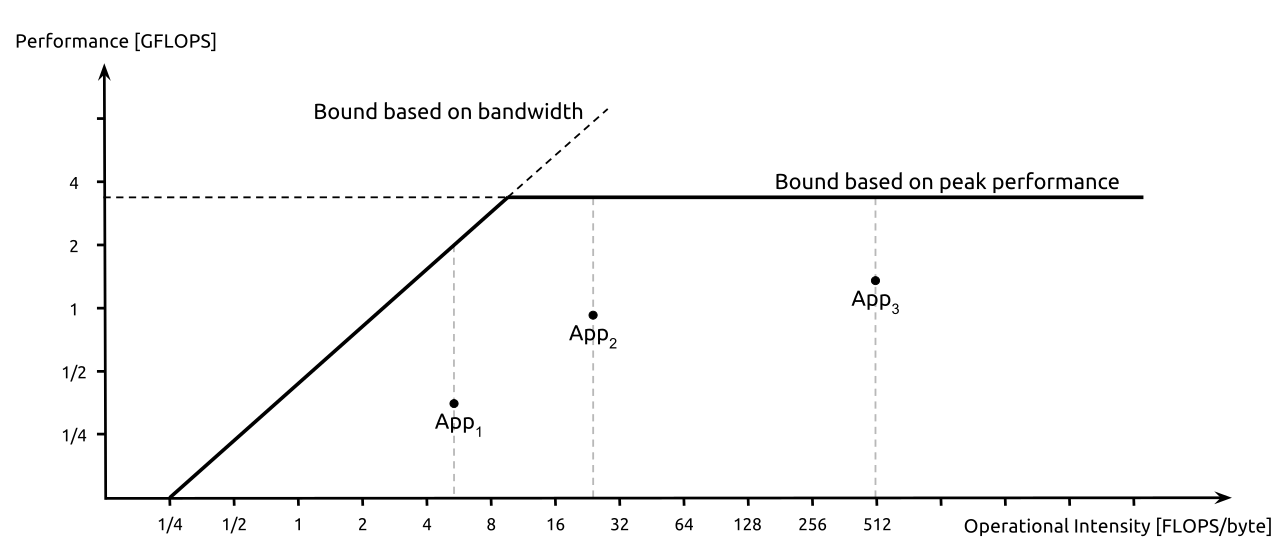
However, there’s a problem with batching -- it slows LLM queries down. The first query in the batch needs to wait for the entire batch to be processed. This is why all-SRAM architectures with a batch size of 1, like Cerebras and Groq, offer extremely low latency. Advocates of all-SRAM architectures argue that latency is extremely important for agentic workloads, where models might be running for hours. If you generate tokens twice as fast, you might cut an agentic workload from 8 hours to 4 hours, which is a meaningful difference.
On the other hand, batching makes workloads more cost-effective. When Nvidia integrated Groq’s LPX chips into their Vera Rubin NVL72 + Groq 3 LPX hybrid clusters, they only used Groq’s chips for high-interactivity, high-cost workloads. For workloads focused on maximizing throughput-per-watt (which is a proxy for cost-efficiency), they just used NVL72 racks, operating using batched processing.
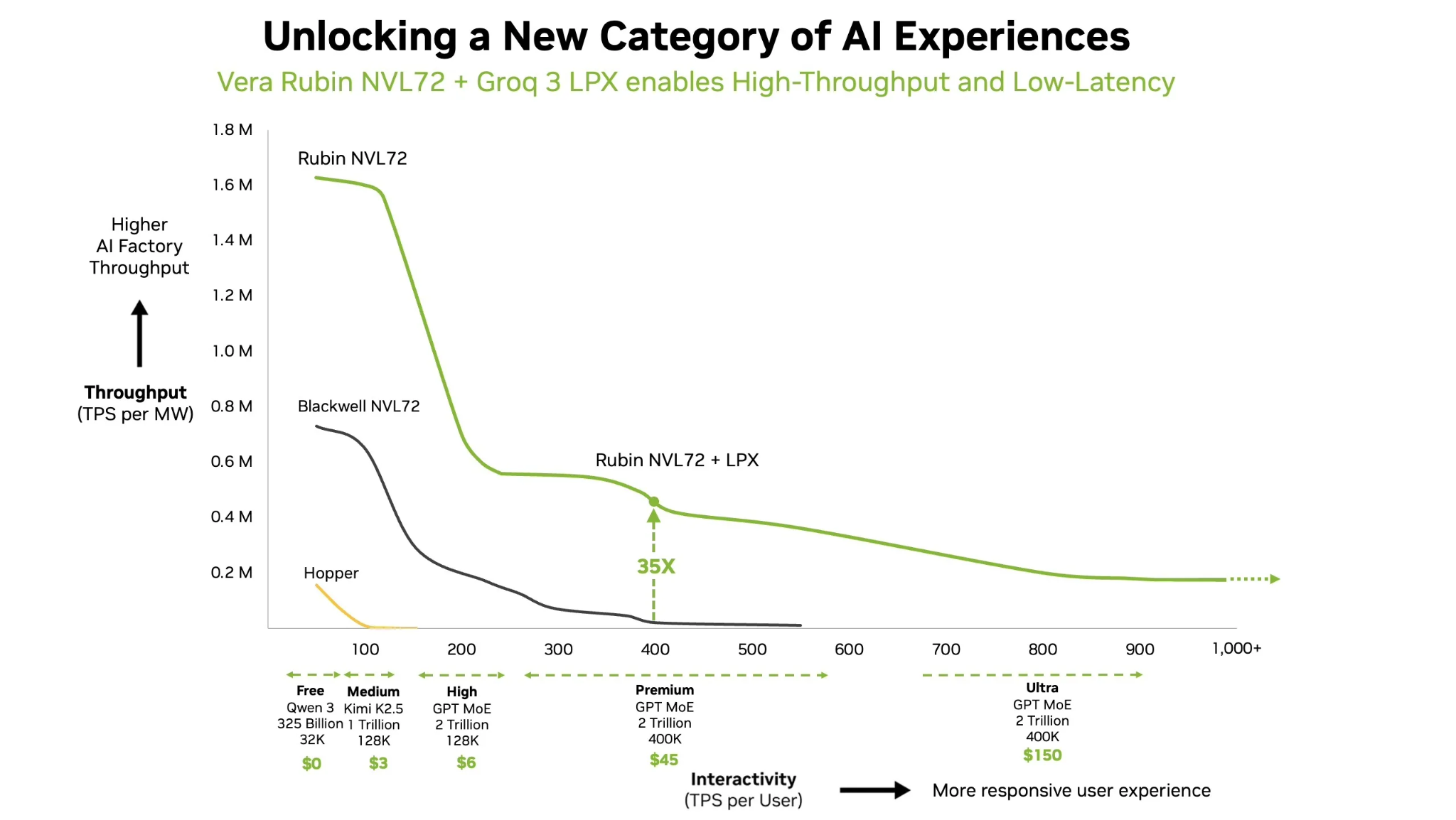
For Tensordyne’s more efficient multipliers to make a major performance difference, they need to be operating in the compute-bound regime on the right of the roofline model. This is a great place to be for cost-sensitive workloads, but high-cost agentic workloads that focus more on speed than efficiency may be too memory-bound to really benefit from Tensordyne’s hardware. However, there’s another advantage that logarithmic computation gives: physically smaller multipliers.
Smaller compute means more memory
If Tensordyne’s compute engine is more efficient, it’s not super important for memory-bound workloads. But if their compute engine is smaller, that allows them to make meaningful changes to the memory hierarchy, too. The space they’re saving with smaller multipliers allows them to fit more SRAM memory on each die.

From there, the performance advantage becomes straightforward. Smaller compute engines result in more on-chip memory, which reduces the number of off-chip memory accesses needed for the same workload, and makes chips more efficient.
It’s unclear how much more efficient this makes Tensordyne’s chips, though. It’s certainly not as big of an advantage as the one they get for compute-bound batched workloads. To estimate the actual advantage, I’d need a lot more technical specifications of the chip itself.
Ultimately, Tensordyne’s chips are offering a clear tradeoff. You have to figure out how to get your models to run on their special chips with their special math, which will limit them to inference workloads. Getting models to work well with logarithmic math is likely going to be difficult and degrade performance, even if they have a special compiler, great support, and help from AI agents. But in return, you get much better efficiency on compute-bound, high-latency inference workloads and somewhat better efficiency on memory-bound, low-latency inference workloads. We’ll see if the market thinks it’s worth the effort. Either way, I think it’s super exciting and cool to see new, weird number formats actually make their way into commercially available silicon.