
How do Nvidia Blackwell GPUs train AI models with 4-bit math?
Bigger chips crunching smaller numbers.

Nvidia recently launched their Blackwell B200 chip, and holy smokes, it’s fast. The company claims that B200 achieves 5x higher training performance and 30x inference performance over their previous chip, the Hopper H100. B200 is also huge. The biggest reason it’s so fast is that it’s about twice the size of H100. B200 is essentially two chips in a trench coat, pretending to be one single chip. So when we look at its eye-popping performance numbers, it’s probably better to compare them to two H100s rather than one.

When you look at FP8 training performance on the spec chart below, B200 is 2.5x faster than Hopper -- which is only 1.25x faster on a per-die basis. How did they get to that “5x faster training” number? Well, B200 has another new feature to double per-die performance over Hopper: 4-bit arithmetic.

4 bits doesn’t seem like a lot. If you’re using those bits to represent integers, you can only count up to 16. But Nvidia’s GPUs feature some really clever technology to squeeze the most utility out of those 4-bit numbers. They’re called “mixed precision tensor cores,” and if you want to understand Nvidia’s dominance at AI, you need to understand how they work.
Tensor Cores: The Secret Sauce
The Tensor Core was first introduced in Nvidia’s Volta architecture in 2017. These specialized cores are designed to accelerate the matrix operations that lie at the heart of most modern AI algorithms. Specifically, they accelerate an operation called “matrix multiply accumulate,” or MMA. In this operation, you multiply two matrices, A and B, and add a third matrix C:

Notably, matrices A and B are stored in a data format called FP16, which only uses 16 bits compared to the normal 32 bits that computers use to represent decimal numbers. That means that the amount of data the chip needs to move and process drops by half. This significantly increased the performance of neural networks!
Nvidia doubled down on this technique with the H100, which went one step further and added FP8 support for tensor cores, doubling performance compared to the V100’s FP16 representation. And it’s clearly continuing to work; B100 halved the number of bits again to FP4.
What can you do with 4 bits?
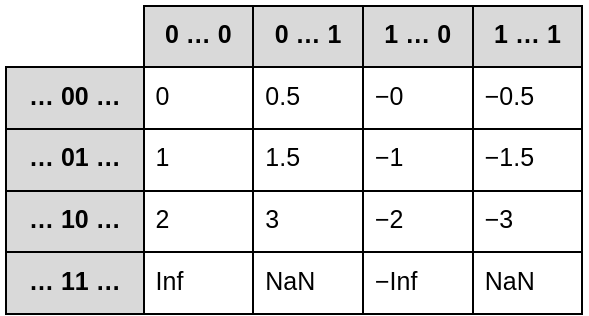
Fitting a number into only 4 bits is difficult. If you’re using IEEE 754-compatible floating point numbers, you’re capable of representing 12 numbers ranging from -3 to 3, plus infinity and NaN (Not a Number, an error code for when you divide by zero).
If the number you want to represent doesn't fall between -3 and 3, it will clip and distort. Even 16-bit floating point numbers have some distortion: if you try to switch from 32-bit numbers to 16-bit numbers, your AI might not train properly. In the example below, certain numbers are too small to be represented by 16-bit floating point numbers, so they round to zero and cause the network to train improperly.

As Nvidia has moved from FP16 to FP8 and now FP4, these distortion issues have gotten worse. Luckily, Nvidia has a solution for this. The tensor cores are capable of scaling your output values so that they do fit into the FP4 range.

By scaling the values, you can transform numbers that would normally fall outside of your numerical range (in red) into numbers that you can represent (in green)! Multiple values share the same scaling factor, which significantly reduces the total number of bits needed. Instead of having many high-precision numbers, Nvidia uses many low-precision numbers and a shared high-precision scaling factor.

Users can manually tune the scaling factors of their networks, but for large networks, this often isn’t feasible, as there are just too many layers with too many scaling factors to tune manually. So Nvidia introduced a new hardware feature to help users leverage mixed-precision training better: automatic mixed-precision scaling.
Automatic Mixed-Precision Scaling
Nvidia chips have multiple ways to automatically scale their low-precision arithmetic, but the most popular is delayed scaling. It’s a simple concept: as you perform FP4 calculations, you note what the largest output value of each calculation is. Call that value amax. Then, you take a rolling average of the most recent amax values to create amax_avg. It’s very likely that the largest value of your next calculation is going to be similar to amax_avg, so you can preemptively scale that upcoming calculation such that values similar to amax_avg don’t get too distorted by the FP4 representation. Nvidia even provides a helpful diagram!

As a user, you can tune how long the history window is, and how you compute the weighted average that generates amax_avg. And it turns out that, for certain operations, this works well! Some operations, like SoftMax during batch normalization need to be in FP32, as do some other network layers, but many layers can be entirely replaced by FP4 operations.
The closer a network can get to being represented entirely with FP4 operations, the closer Blackwell’s training performance can get to that eye-popping 5x number Nvidia cited. And luckily, there’s already some research showing that networks can train with FP4 operations without significant loss of accuracy. If those results can scale to GPT-4-scale networks, then Nvidia has a huge advantage over other datacenter AI chips, which, as far as I can tell, don’t yet support these FP4 operations.
Nvidia is dominant in the AI datacenter, but it’s clear from Blackwell that they’re not complacent at all. They’re combining hardware improvements and algorithmic insights to deliver impressive performance improvements year-over-year. And they’re working with top AI labs to ensure that researchers and model-builders can maximally leverage their new capabilities. Personally, I think that Nvidia’s reign as the AI chip kings is far from over.