
Why did Tesla Dojo fail?
Building training chips is a unique challenge.

This week, news broke that Elon Musk is shutting down the Dojo supercomputer it was using to train its full self-driving models. Part of the reason for the shutdown was the departure of a number of key executives, who left to found a startup called DensityAI. However, I think there are clear technical reasons why it didn’t make sense for Tesla to keep developing their own training chips in house.
And Tesla isn’t the first company to have given up on training. Groq, Cerebras, and SambaNova all used to be targeting training as well as inference, but have pivoted, one by one, to a pure inference focus. This isn’t surprising; not only are there unique technical challenges required to build training chips, but also, moving training runs to new hardware is an immense financial risk for any company. Ultimately, I think Tesla is making the right decision to focus its custom silicon efforts on inference and leave training to Nvidia silicon.
The risk of failed training runs
Training AI models is hard. It’s also usually very, very expensive. Training GPT-4 scale large language models can take many months and cost over $100 million dollars. But training isn’t just a matter of spending a lot of money on compute and waiting until the model is ready. During the process of training, engineers monitor the network’s accuracy1 to ensure that the model is continuing to learn as new data is being fed into the training process. If the network accuracy suddenly starts dropping despite the model getting more data, the model may be failing to converge, which could put the entire training run at risk.
There are a lot of potential causes for convergence failure when training large models, but numerical stability is often a key reason a training run may go wrong. As models are trained at lower and lower precisions, the specific way low-precision numbers are handled in hardware starts to affect how well a training run converges. And unfortunately, this is not something that is constant across different pieces of hardware. Nvidia GPUs have automatic mixed-precision features that will automatically tune mixed-precision models to maximize tensor core utilization, scale the loss to avoid non-convergence, and handle issues with out-of-bounds gradient values.
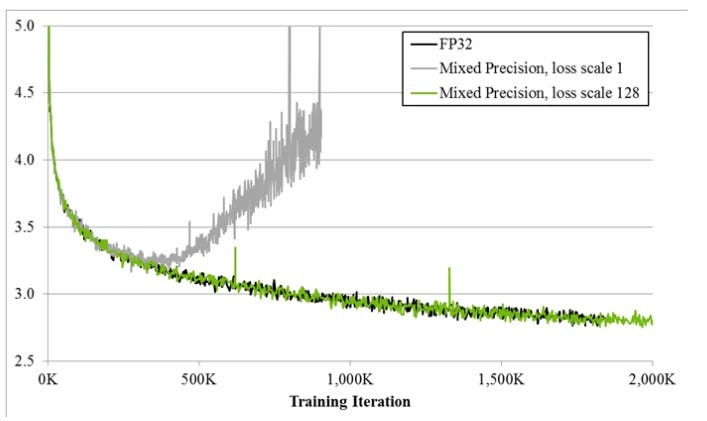
Existing training pipelines for large models rely on these hardware-specific features. If you want to shift your training process to a completely new piece of hardware that handles mixed-precision arithmetic differently, like the Tesla Dojo, you’ll also need to re-develop your training pipeline. And if you re-develop your training pipeline, there’s a good chance you run into non-convergence issues the first few times you try to actually train models. For large models, this is a hugely expensive risk to run.
Notably, this isn’t an issue for inference. While models do need to be optimized for inference on specific pieces of hardware, that optimization process is much faster and easier. Instead of developing a new hardware-specific training pipeline and having to wait weeks to ensure that it’s numerically stable, an inference implementation can be benchmarked in minutes by simply running forward passes through the network. This is part of the reason why we see much more hardware diversity in inference than in training; put simply, it’s much easier and less risky to port an inference pipeline to a new chip than a training pipeline.
Thus far, Tesla’s training process for their FSD models has leveraged both Tesla Dojo chips and Nvidia chips, which means that Tesla has had to maintain two complex training recipes for large models that each account for the specific quirks of two different pieces of hardware. I believe that simplifying to training purely on Nvidia hardware, while using its custom AI5 and AI6 silicon for inference, makes a lot of sense for the company.
But there’s another piece of this story: all the executives from Dojo who left the company to found a startup called DensityAI. If training on new hardware is so difficult, why are they starting a company to do just that?
What is DensityAI, anyways?
DensityAI has been pretty secretive thus far. According to Bloomberg, they’re a hardware company focused on industries like automotive and robotics. They’re hiring for roles focused on the datacenter, not on the edge -- so they’re not building inference chips to go in cars or robots. Instead, they’re building infrastructure for training models. But a key clue comes from some of their job postings which specifically mention GPU programming and CUDA programming. At the same time, their only open hardware roles are focused on packaging, PCB design, and thermal management. To me, this indicates that DensityAI isn’t trying to build new chips to replace Nvidia GPUs. Instead, they’re trying to build new datacenters optimized for large-scale training using existing GPUs.
On one hand, this makes some sense. Most automotive manufacturers and robotics companies don’t have the resources or talent to maintain large datacenters for training state-of-the-art models for autonomous systems. DensityAI could make significant inroads with companies that want access to the best AI models for autonomy, but don’t have the capacity to train those models themselves.
However, it’s also unclear to me why autonomous vehicles and robots require specialized datacenters built from the ground up. Many hyperscalers like Amazon, Google, and Microsoft already have compelling cloud datacenter offerings, which I would assume can handle training what is essentially a very large and complex computer vision model. It could be the case that certain automotive reliability and security standards, like ISO 26262 or ISO/SAE 21434 could require specialized, secure training for autonomous driving models that would make the hyperscalar cloud solutions non-viable -- but to answer that question, we’ll have to wait for DensityAI to fully come out of stealth.
Ultimately, it seems like the DensityAI team has learned from Tesla’s failures and stayed focused on building the best training systems they can using existing GPU hardware, building off of existing state-of-the-art training pipelines, rather than taking the massive risk of building new training hardware from scratch and sinking months and millions of dollars into training runs that fail to converge.
Technically, they monitor the training loss, validation loss, and perplexity, as well as other task-specific metrics.