
Sabotaging AI models with GPUHammer
AI chips continue to be insecure.

GPUs and AI chips continue to be a huge area of investment, from edge chips like the Jetson to datacenter behemoths like the B200. But one area of research that’s been continuously overlooked is the security of these systems. If we want GPU-powered systems to be making medical decisions or piloting drones, they should be secure. I’m not the only person saying this: since mid-2024, OpenAI has been pushing for secure and trusted GPUs to protect their models. But what OpenAI is proposing simply isn’t secure enough.
Specifically, OpenAI and Nvidia are advocating for trusted execution environments, which keep AI weights and inputs encrypted until they’re securely inside the GPU ready for processing. This is an important security feature, but it has its limitations. Firstly, TEE implementations are often flawed, which can undermine the security they offer. But more importantly, TEEs can’t protect against side-channel attacks like power analysis and electromagnetic analysis -- attacks that GPUs are vulnerable to. Luckily, most side-channel attacks on GPUs require physical access to the chip to attach power or EM probes, making them only suitable for attacking edge devices.
Recently, though, researchers have identified a GPU hardware vulnerability that can be carried out fully remotely on a single shared piece of hardware. It’s called GPUHammer, and it’s an adaption of the classic rowhammer attack to GPU memories. When multiple processes are sharing the same GPU, a malicious process can mount an attack to flip bits in rows of memory it doesn’t have access to, and sabotage the performance of machine learning models running in a different process. Today, we’re going to talk about how it works, what it means, and how it should affect GPU design going forwards.
What is rowhammer, anyways?
Rowhammer is an attack on DRAM that manipulates the underlying physics of the memory cells to flip bits in rows of memory that an attacker shouldn’t have access to. In DRAM, each memory cell is implemented using one capacitor and one transistor, in a design called 1T1C memory. All of these capacitors are packed together so densely in modern DRAM that there’s a meaningful electrical coupling between capacitors in different rows of the memory.
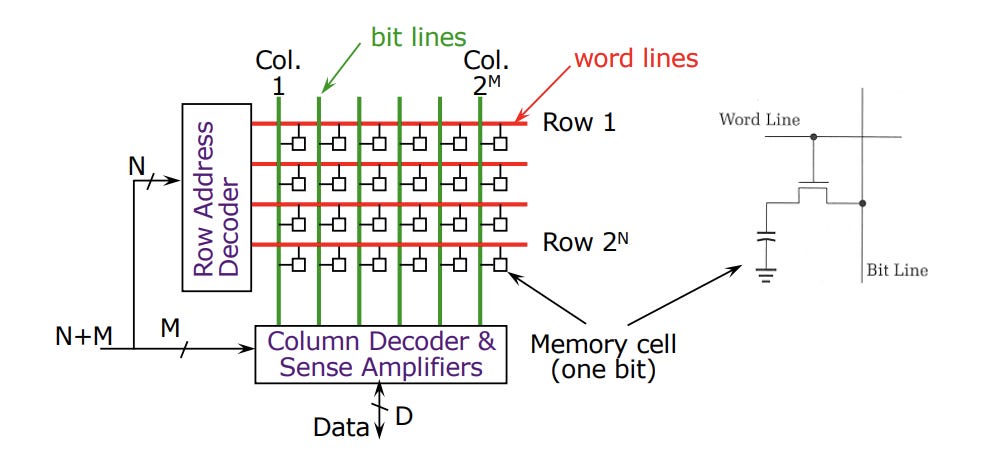
If a malicious process repeatedly reads from the same row in memory, it can disturb the values stored in the memory cells next to that row. Not only can this corrupt data that the malicious process doesn’t have access to, but it can even be used to perform sophisticated attacks like privilege escalation.
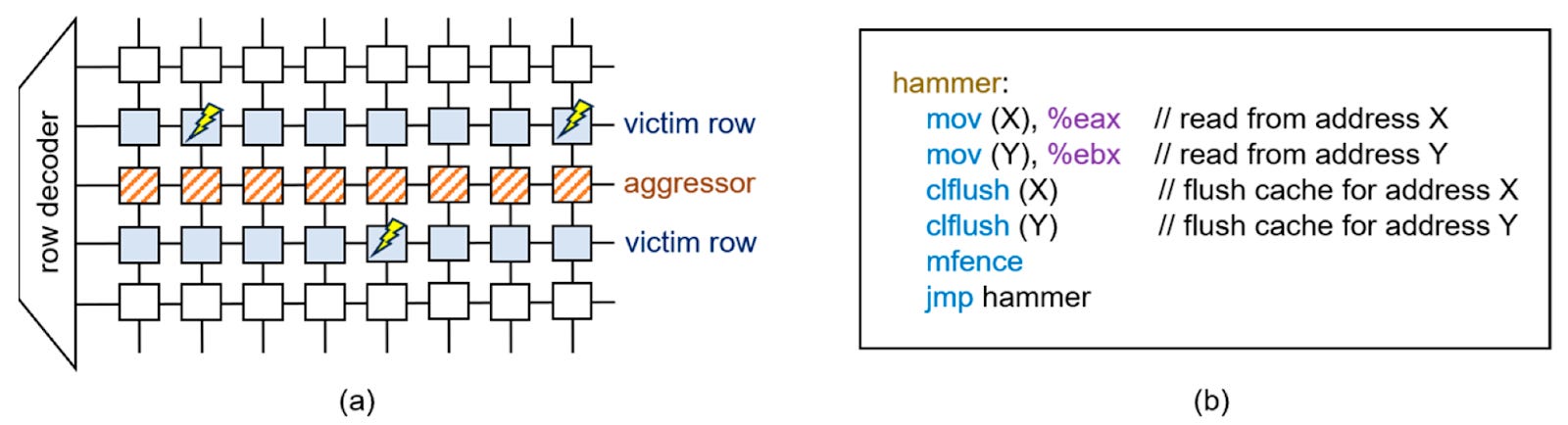
DRAM manufacturers have been working to mitigate rowhammer using error correcting codes, automatic refreshing of possible victim rows, and memory scrambling. At the same time, security researchers have reverse engineering scrambling algorithms and finding more complex hammering patterns that can outwit DRAM mitigations. But thus far, all of the research around rowhammer has been focused on CPU memories.
How is GPUHammer different?
While GPUs also use DRAM, they don’t use the same DDR and LPDDR memory that CPUs do. Instead, they use a special kind of DRAM optimized for GPUs, called GDDR memory. GDDR has both a faster refresh rate and a higher latency than DDR and LPDDR memory, which makes hammering harder. At the same time, nobody has taken the time to reverse engineer memory scrambling for GPUs. So while rowhammer should conceptually work on a GPU, the GPUHammer authors are the first researchers to put in the legwork to overcome those obstacles and actually develop a real GPU rowhammer attack.
GPU memory scrambling is uniquely difficult, because Nvidia GPUs never expose physical memory addresses to user-level CUDA code. However, the GPUHammer authors used memory latency patterns to reverse engineer the physical memory addresses from the virtual memory addresses.
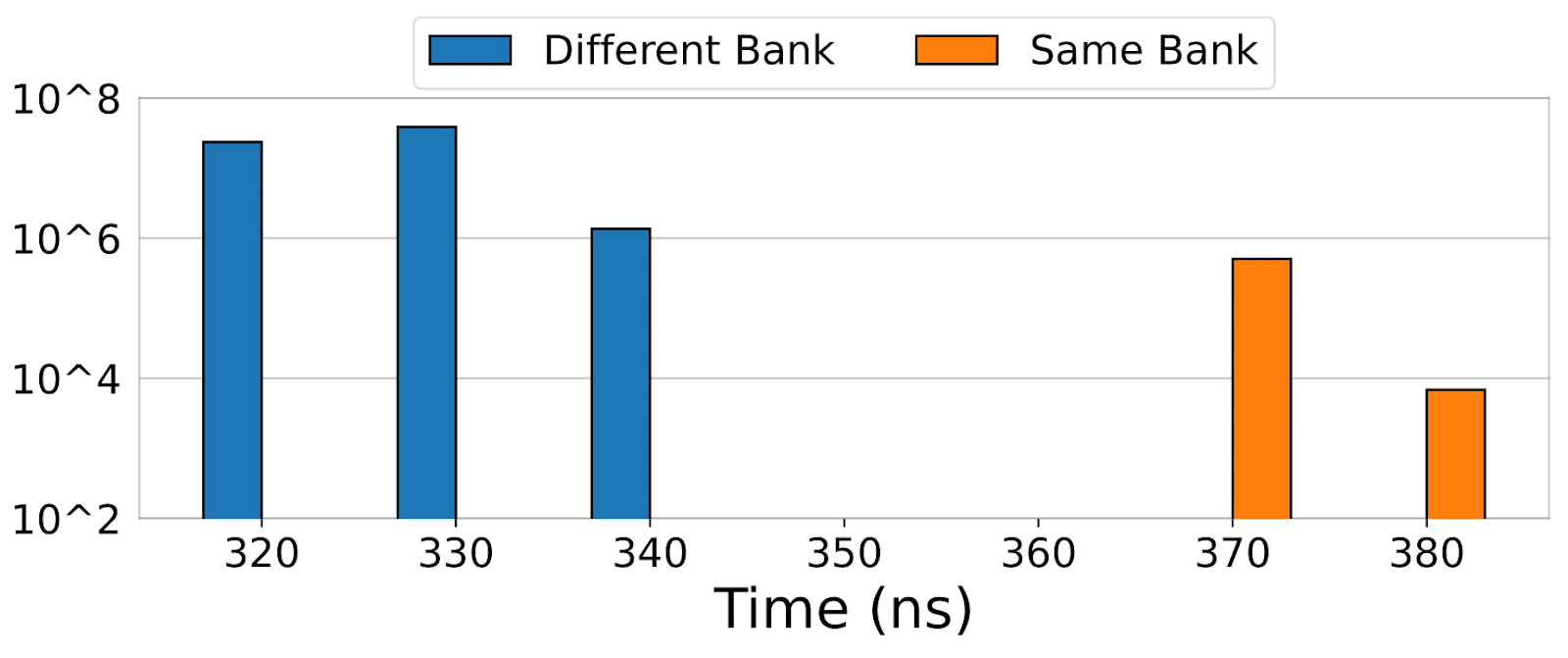
Another big challenge is that GPU memory accesses are slower than CPUs, which makes hammering much harder. If you try to have a single threaded process repeatedly access the same memory, there won’t be enough memory accesses fast enough to cause a rowhammer effect. However, by leveraging warp-level parallelism, multiple warps can be issuing memory reads simultaneously, and cause enough hammering to actually flip bits in the victim rows.

These techniques let the researchers isolate which memory addresses to target with a rowhammer attack, and hammer those addresses hard enough to flip bits in adjacent rows. To prove how devastating this attack could be, they used the attack to flip the sign bit in the weights of a machine learning model running in a different process on the shared GPU. This reduced the accuracy of several machine learning models by over 80%.
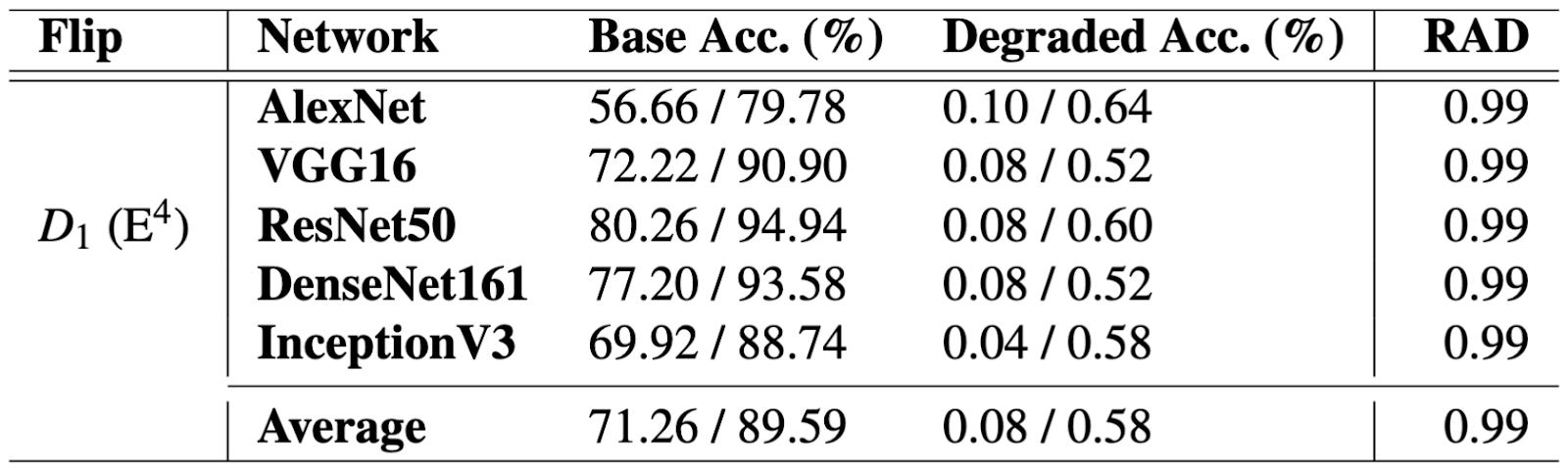
Essentially, if an attacker can successfully carry out a GPUHammer attack, they can totally sabotage the output of an AI model running on a shared GPU.
Does this matter?
As AI becomes more and more important and entrenched in our lives, the ability to tamper-proof AI models also becomes important. Thankfully, though, GPUHammer isn’t going to suddenly break ChatGPT. Firstly, GPUHammer has thus far only been demonstrated on A6000 GPUs with GPDDR6. The large cloud H100 and B200 cloud GPUs used by state-of-the-art AI models leverage HBM that has stronger on-die error correction and rowhammer prevention. More importantly, though, most cloud services don’t offer shared GPU workloads; instead, each user gets a certain number of dedicated GPUs, which would mitigate this sort of attack.
However, there are cases where single GPUs run multiple processes concurrently! WebGPU lets websites leverage GPU capabilities of a user’s computer. In theory, a website with WebGPU could perform rowhammer attacks when opened, corrupting data for other concurrent GPU processes including AI models. More generally, whenever multiple processes are sharing the same GPU, that could open the door for a GPUHammer vulnerability.
What do we do now?
GPUHammer just highlights the lack of attention that hardware security has gotten in the world of GPUs and AI accelerators. Most CPUs have supported complex trusted execution environments, secure boot protocols, inline memory encryption, and other security features for years. Security conscious edge microcontrollers for applications in payments, crypto wallets, defense, and critical industry come with even more protections against complex side-channel attacks. CPU DDR memory has been engineered with rowhammer mitigations for almost a decade. But outside of a small number of research papers, building secure AI chips is not a major industry focus.
I think that’s a major problem. As AI starts to influence more and more aspects of our lives, we need to make sure that the hardware it’s running on is secure from first principles. AI chips need post-quantum secure boot, side-channel protections, secure memory, and other key features that are implemented in other high-value, security conscious chips. If we can put that level of security into the chips powering the credit card you use to buy a burrito, we should be able to put it into the chips running AI models for the defense industry.