
Solving Optimization Problems with Asynchronous Oscillators on FPGAs
Energy-based computing, democratized!

Oscillator-based optimization solvers are a new and exciting paradigm for solving hard computational problems. By leveraging coupled oscillators instead of conventional digital logic, they can be extremely efficient. Unfortunately, they’re currently only available to graduate students and postdocs in the small handful of labs that are researching these architectures. Today, that changes: by implementing a large number of ring oscillators on an commercially available FPGA, and getting them to interact with one another, I’ve demonstrated a coupled-oscillator solver that can solve certain optimization problems very quickly.
With an open-source FPGA implementation that runs on AWS F1 FPGAs, anybody can start experimenting with this novel paradigm for computation, which has applications in finance, logistics, drug discovery, and even machine learning. I’m calling it DIMPLE: Digital Ising Machines from Programmable Logic, Easily! We have a Discord, and if there’s interest, I’m looking into launching a cloud service to let anybody easily run workloads on these systems at a low cost. All of the relevant links are hosted at unphased.ai.
This is going to be a fairly dense and technical article, so here’s a bit of a roadmap. The first half is tailored to technically-minded folks who don’t have a background in FPGAs or Ising machines. It explains how the DIMPLE solver works to solve a basic problem, so hopefully this should be enough of a tutorial to get folks excited to try running their own workloads on it. The second half is more of a research pre-print, with the sorts of profiling data you’d expect from a scientific paper on the subject: still exciting, but less accessible to folks without a EE background. If you’re a researcher with a background in coupled-oscillator computing, feel free to jump ahead to Architecture, Methods, and Results.
Let’s get started!
How does DIMPLE solve optimization problems?
The DIMPLE solver is capable of solving a large number of optimization problems, but our motivating example is going to be the Maximum Cut problem. Maximum Cut is easy to understand conceptually, but it’s NP-complete, which means it’s extremely hard to solve quickly. The problem is simple: given a graph made up of edges and nodes, use a single, contiguous line to cut some number of edges and split the graph into two sections. We’ll call these sections Black and White. The line that cuts the most edges without doubling back on itself constitutes the “maximum cut.” For a simple 5-node graph with 6 edges, the max-cut looks like this:

{kind=link}
Normally, you’d calculate this solution with a complex graph partitioning algorithm. But it turns out, we can actually build a machine to find the maximum cut for a graph using the power of physics. According to thermodynamics, a physical system always wants to find the lowest energy state. If we can find a way to represent the graph with a system where the maximum cut corresponds to the lowest energy state, we can solve this problem easily. And it turns out that we can do that using oscillators.
It’s worth noting that this core idea is not mine! There’s an entire body of research around building physical machines, called Ising Machines, to solve optimization problems [1][2][3][4]. The DIMPLE solver implements an Ising Machine in a new way, but to understand that, we first need to understand how these machines work in general.
Representing Maximum Cut with Oscillators
How do we turn a graph problem into a physical machine capable of solving that problem? One building block we can use is an oscillator. In our case, we’ll use a ring oscillator, because they’re simple to build out of basic logic gates. Each ring oscillator generates a square wave at node A with a frequency f, period T, and phase ɸ, while also generating the inverse of that square wave at node !A, with the same frequency but a phase of 180°ɸ.1

If you look at the 5-node maximum cut solution above, we want to maximize the number of edges that connect Black nodes to White nodes, while minimizing the number of edges that connect Black nodes to Black nodes and White nodes to White nodes. Recall that we want the maximum cut solution to be the lowest energy state of the machine. Thus, we want Black-White edges to consume a low amount of energy, while Black-Black and White-White edges should consume a high amount of energy.
Let’s represent White nodes in the graph as oscillators with phase ɸ, and Black nodes with oscillators with phase 180°ɸ, so Black and White nodes have opposite phases. Now, let’s attach some resistors to the oscillators.

For a Black-White edge, we connect node A of the White oscillator to node !B of the Black oscillator. When node A of the White oscillator has phase ɸ, and node B of the Black oscillator has phase 180°ɸ, the voltage across the resistor, VR, is zero. This means that no current passes through the resistor, and no energy is spent on that edge.

For a White-White edge, we connect the oscillators in the same way. Because both White oscillators have phase ɸ, there is always a voltage across the resistor. This means that current is always flowing through that resistor, so that edge is consuming energy. The same high-energy behavior occurs for a Black-Black edge.
By adding a resistor for each edge in the 5-node graph, we’ve built a machine where the lowest energy corresponds to the highest possible number of Black-White edges. This means that the system will automatically converge to this state, regardless of where the phases the oscillators start!2 And this state corresponds to the maximum cut solution on the graph.

This resistor-based technique is essentially what Lo et. al. do in their Nature paper!3 There’s one issue with this technique, though: it requires resistors, which are analog components. If you want to build one of these machines, you have to either build it with a breadboard, or build custom chips. Neither solution is cost-effective or scalable.
On the other hand, the DIMPLE solver is cost-effective or scalable, because it uses a different technique to represent oscillator interaction. And this technique makes it possible to implement DIMPLE on a commercially available FPGA.
Oscillator Interactions on an FPGA
An FPGA is essentially a chip with a large number of logic gates on it. You can connect these logic gates in any pattern you want to build custom digital circuits.4 Because a ring oscillator is constructed out of NOT gates, it’s actually fairly simple to implement one on an FPGA. The challenge in building a maximum cut solver lies in replacing the analog resistors with digital logic gates.
Delay-based Resistor Model
If we want to build a “digital resistor,” we first have to understand more deeply how the analog resistors work in our example above. To simplify the problem, we’ll construct a single ring oscillator, which oscillates between 0V and 1V. We’ll observe the voltage at two different wires, A0 and A1. We’ll also create a third wire, B, and connect B to 1V. In practice, B would actually be connected to a separate ring oscillator, but keeping B at a constant value simplifies the analysis.
Now, we construct two different situations. In the first, B and A1 are unconnected. In the second, B and A1 are connected by a resistor.

Let’s consider the behavior of the system at the instant A0 switches from 1V to 0V. At this point, the voltage at A1 is 0V, and the NOT gate between A0 and A1 is about to start making A1 switch from 0V to 1V. In Scenario 1, with no resistor, we’ll call the amount of time it takes for A1 to switch from 0V to 1V T1.5
In Scenario 2, however, there are two forces acting to make A1 switch from 0V to 1V. The NOT gate between A0 and A1 is causing A1 to switch, but the resistor connecting A1 to B is also pulling the voltage at A1 towards the voltage at B. This means that the time, T2, for A1 to switch from 0V to 1V is shorter than T1, due to the resistor.

We see similar behavior when A1 is switching from 1V to 0V, but in reverse. In Scenario 1, the NOT gate causes A1 to switch from 1V to 0V in time S1. In Scenario 2, the resistor and the NOT gate are pushing A1 in opposite directions: the resistor is trying to prevent A1 from switching from 1V to 0V. This causes the switching time in Scenario 2, S2, to be slower than S1.
Thinking about the effect of the resistors in terms of timing rather than in terms of energy is definitely less intuitive, but it’s the key insight behind DIMPLE. An FPGA can’t implement resistors using logic gates, but it can implement delays. That means we can make a “digital resistor!”
Building the Digital Resistor
The basic principle of the delay-based resistor model is as follows: “If A1 is switching to be the same as B, speed it up. If A1 is switching to be the opposite of B, slow it down”. And there’s actually a simple logical operation to determine the “same-ness” of two logical values! An XNOR gate always outputs a logical 1 if the two inputs are the same, and a logical 0 if the two inputs are different.
So to build our “digital resistor,” we take the XNOR of A0 and B, and depending on the result, select which path the A0 signal takes to get to A1 using a multiplexer. If A0 is the same as B, we know that A1 is about to switch to the opposite of B, so we want to select a slow path between A0 and A1. We make that path slow using many back-to-back NOT gates, which each have a small propagation delay.
If A0 is different from B, we know that A1 is about to switch to have the same value as B, so we want to select a fast path between A0 and A1. We make that path fast by avoiding the many back-to-back NOT gates, and instead just use a single NOT gate. So our very simple digital resistor looks like this:
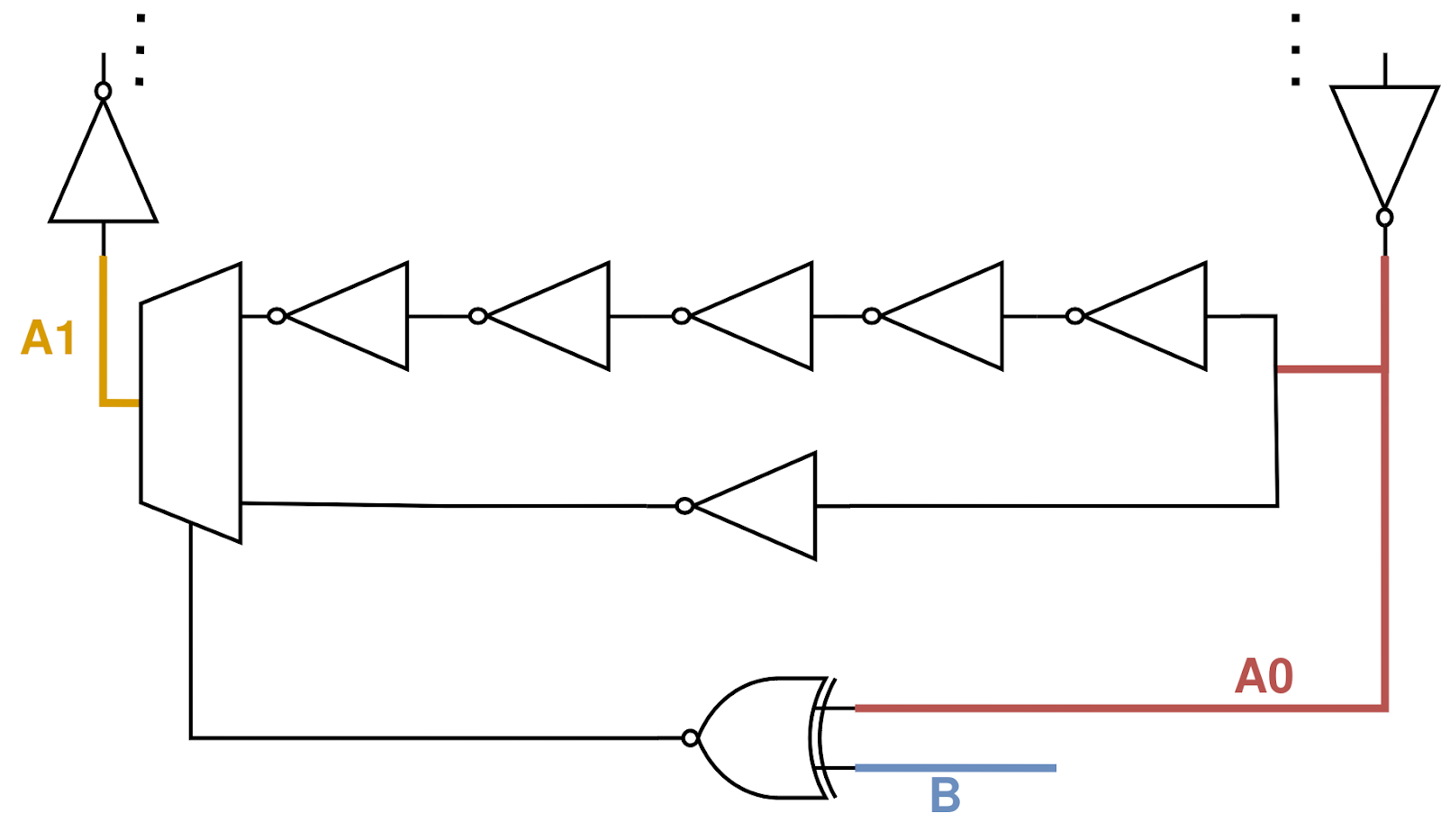
It turns out that if we build a system using these digital resistors instead of analog resistors, this system is actually able to solve the Maximum Cut problem too!6 This is, to my knowledge, a novel technique that’s currently only implemented in the DIMPLE solver.
There are a number of advantages to this all-digital method. First of all, it’s much more accessible! Anybody can load this design onto a commercially available FPGA and start leveraging oscillator-based computing. It’s also highly scalable. Because DIMPLE only consists of logic gates, it can work with any FPGA and any silicon process node.
However, there are some downsides to this approach compared with the analog approach, though. Delay cells, XNOR gates, and multiplexers are larger than simple resistors, so for a given process node and spin count, the analog approach would likely outperform the digital one. As oscillator-based computing technology continues to evolve, I think this digital approach could serve as a middle ground between analog oscillator-based solvers and conventional CPU or GPU solvers. It’s almost as good at solving these sorts of problems as an analog oscillator-based solver, and almost as accessible as a powerful CPU or GPU.

To be clear: right now, both analog and digital oscillator-based solvers often underperform CPU and GPU-based solutions; however, I think there’s a lot to be optimistic about as this technology continues to mature! I’m just adding my small contribution to the larger body of research on coupled-oscillator computing.
Potential Applications
What’s particularly exciting about DIMPLE is that all of oscillator-based computing has potential real-world use cases! Solving hard graph optimization problems like Maximum Cut turns out to be widely applicable to many fields, like drug discovery, finance, logistics, and machine learning.
Personally, I’m particularly excited about machine learning applications, because one of the biggest downfalls of emerging, novel architectures for machine learning is their lack of accessibility. In graduate school, I worked with a chip called Braindrop, which was a state-of-the-art neuromorphic chip designed to run machine learning workloads while consuming less than a picojoule per synaptic operation. But nobody outside of our lab and our close collaborators got to actually use the chip, so algorithms didn’t get developed to leverage its unique strengths. I see this challenge happening again and again with novel machine learning chip designs: usually, highly novel designs require custom chips that are hard to make accessible. By being both highly novel and deployable on an FPGA, DIMPLE solves that accessibility problem, and enables anybody to develop new algorithms to leverage its unique hardware advantages.
I’ve been working hard to make DIMPLE as accessible as possible. Not only is the entire design open source, but I’ve also added a PyTorch frontend, based off of the simulated-bifurcation package. You can define the weighted adjacency lists for graph problems as PyTorch tensors, and call the Minimize function to find the lowest energy state using the DIMPLE solver. For more info on how the software stack works, take a look at “Controlling DIMPLE with PyTorch.” Feel free to build and install the FPGA images and PyTorch solver yourself, and to contribute PRs to the repositories with any features you think would be useful!
If you want to join the community of developers and users, join our Discord! There are also a number of open issues on GitHub that I’d love some help on. If you’re interested in a cloud environment for easily running workloads using FPGA-based DIMPLE solvers, let me know! All of the relevant links are hosted at unphased.ai.
Now for the more technical part of the post! Prepare to read something a bit more like a research paper.
Architecture, Methods, and Results
The DIMPLE solver architecture
The DIMPLE solver uses a number of techniques to efficiently implement all-to-all oscillator coupling on an FPGA. The architecture consists of a 64x64 array of buffers, connected by all-digital, delay-based coupled cells. An 8-spin example is shown below; buffers are shown as circles, while coupled cells are shown in red and blue. Different colors are used purely to differentiate overlapping lines; all coupling cells are equivalent.

The k-th Ising spin is represented by the horizontal oscillator in the k-th row of the core matrix. Each spin is initialized to either +1 or -1, as described in shorted_cell.v. Every column in the core matrix consists of (N-1) directional coupling cells, with the coupling distance equal to the column index; column 1 has a coupling distance of 1, and so forth. The output of the last column loops back around to the initialization column, where it is inverted, thus forming a ring oscillator loop.
At each coupled link in our core matrix, we implement our digital phase-coupling cell, coupled_cell.v. Based on the coupling weight, rising and falling edges of incoming signals are either slowed down or sped up as they pass through the coupling cell. This serves to bring positively-coupled oscillators closer in phase to one another, and negatively-coupled oscillators farther in phase from one another. The coupling logic is carefully designed to prevent glitching or ringing behavior, as the circuit runs entirely asynchronously. Delay elements are constructed with back-to-back FPGA lookup tables, which are implemented using the dont_touch directive to prevent them from being removed by the synthesis flow. A more in-depth explanation of the coupled cell is provided in the “Oscillator Interactions on an FPGA” section above.
The physical layout of this array is important; physical arrangements where some oscillators required more routing resources than others resulted in poor system performance. When the entire core matrix is automatically routed by Vivado, different structures result in different performance. Our GitHub repositories contain some other potential array structures, including a square matrix similar to Lo. et al’s design, as well as benchmark data for those structures. However, it does seem like there is a bit of luck involved when it comes to Vivado automatically routing the design well. More compact array structures could potentially be achieved by leveraging manual routing.
Notably, our digital coupling structure allows us to create asymmetric coupling, where one oscillator affects a second oscillator, without being affected itself. Because resistors and capacitors are symmetric devices, this cannot be achieved using resistive or capacitive coupling.
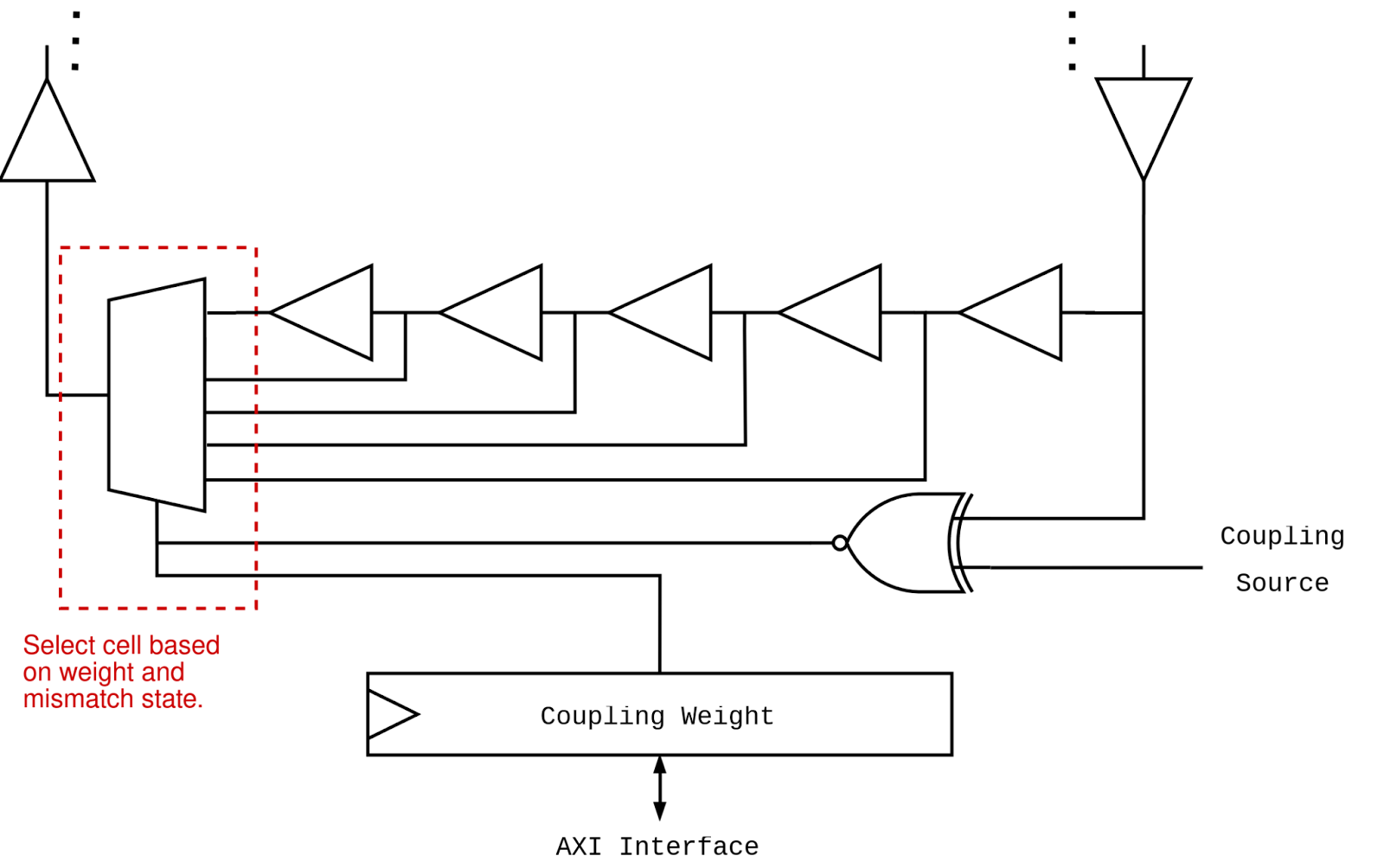
The 64th spin in the core matrix represents the local field, h, in the Ising model, and also acts as the reference spin against which all other spins are measured. The state of the local field and every other oscillator are compared during every cycle. If the two are currently in phase, a counter for that spin increases; if they are out of phase, the counter decreases, as shown in sample.v. This allows us to measure the evolution of the phases of the different oscillators over time. In practice, a 4-stage synchronizer is used to ensure that no metastability appears in the synchronous counter logic.
Scaling with Increased Spin Count
Chou et. al. and Vadlamani et. al. developed analyses of the scaling properties of coupled oscillator systems that can also apply to DIMPLE. According to Vadlamani, while the area consumption of the all-to-all coupling scheme scales as O(N2), the time-to-solution should scale as O(2√N). According to the analysis by Chou, coupled oscillator systems will start to outperform conventional solvers once spin counts cross about 200 spins. Hopefully we can build a 200+ spin version of DIMPLE one day!
Asymmetric Coupling and Non-Equilibrium Dynamics
Support for asymmetric coupling gives DIMPLE the ability to represent additional kinds of systems and dynamics compared to conventional analog Ising machines. Notably, asymmetric spin systems may introduce limit cycles into the system behavior, where the spin states oscillate between multiple values, rather than converging to a single stable solution. By sampling spin values multiple times while the system is oscillating, we can determine the relative probabilities for each spin to take on the value +1 or -1. This article doesn’t discuss potential applications of asymmetric coupling, but here are two great articles on asymmetric spin-glass systems for those of you who are interested!
A unifying framework for mean-field theories of asymmetric kinetic Ising systems. Aquilera et. al.
Nonequilibrium thermodynamics of the asymmetric Sherrington-Kirkpatrick model. Aquilera et. al.
Transparent Latches to hide Combinational Loops
AWS F1 FPGA instances have guardrails in place to prevent users from deploying designs that contain combinational loops. These guardrails are important for system security; designs with combinational loops can enable denial of service attacks and side-channel attacks. DIMPLE consists of many combinational loops, and would normally be unable to be deployed on AWS F1 FPGA instances due to these guardrails. Luckily, security researchers have found workarounds that enable users to implement combinational loops in such a way that AWS F1 FPGA instances do not recognize that a combinational loop is present.
In DIMPLE, we use the transparent latch technique proposed by La et. al. Every coupled cell includes a transparent latch placed such that the combinational loops both inside and outside of the cell are hidden from the synthesis tooling. We also add a number of special timing directives to mark all of these transparent latches as false timing paths, so that the synthesis tool doesn’t spend effort optimizing these paths.
Controlling DIMPLE with PyTorch
DIMPLE can be controlled using our fork of the simulated-bifurcation python package. Not only does this package provide a set of straightforward utilities for dealing with Ising models, it also serves as a reference solver against which to compare DIMPLE. We’d really like to thank the authors of that package for their amazing work.
We use Python CTypes to call a shared C library with Python, as shown in ising.py. Currently, the C library is a very simple peek-poke interface, with most of the complexity handled by Python; performance could likely be improved by moving more of the logic to program and manage the DIMPLE solver to the C library.
Automatic Spin Merging and Spin Rounding
To make programming the DIMPLE solver easier, we include options to automatically re-scale and round all weights to the solver’s dynamic range. This feature makes it possible for users to have a more hardware-agnostic approach to configuring the solver, rather than having to be aware of the specific weight resolution supported by the hardware. Currently, the package warns the user when rounding takes place, but does proceed with running the solver.
For small Ising matrices, having a large number of unused physical spins often results in poor performance, as discussed in Lo et. al. We adapt their spin-merging scheme, which represents one logical spin with multiple tightly-coupled physical oscillators. Again, we built an automated, no-touch method that automatically merges spins when possible, rather than requiring users to manually configure spin merging. Manual spin-merging is still possible for advanced users.
Measurement Results
To determine the quality of solutions produced by the DIMPLE solver, we generated a number of different 64x64 Ising problems, and programmed them into the DIMPLE matrix. The solutions from the DIMPLE solver were compared to reference solutions, generated using the simulated-bifurcation python package with a large number of annealing steps. For each trial, the value of the Hamiltonian of the solution generated by the DIMPLE solver was normalized by the value of the Hamiltonian of the reference solution, to create a figure of merit of “Normalized Solution Quality”.
Notably, we were unable to take measurements of power consumption or the effect of temperature, as the DIMPLE solver is hosted on an AWS F1 FPGA instance. Future work may involve developing a version of the DIMPLE solver for a smaller, more affordable FPGA which is amenable to these measurements.
Effect of Graph Sparsity
We first varied the sparsity of the J matrix, to determine the effect of sparsity on the solution quality. In Figure 1, each dot corresponds to a solution attempt by the DIMPLE solver. In between each solution attempt, the mapping between physical spins and logical spins was randomized. Dots sharing the same color and sparsity value are different solution attempts for the same Ising problem instance, while dots of different colors are solutions for different Ising problem instances.
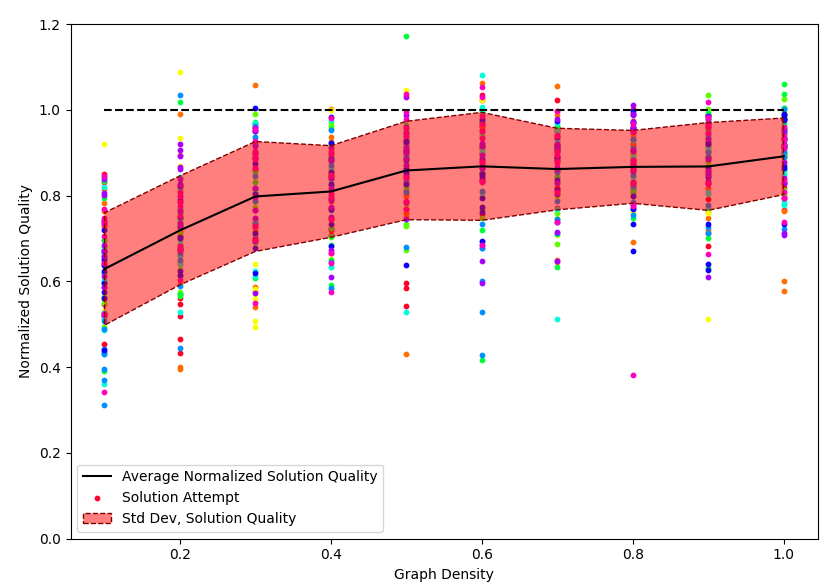
We observed that the higher the density of the matrix was, the higher the quality of DIMPLE's solutions were. This result matches what was observed by Lo et. al. for their analog coupled oscillator solver. And their theories explaining this behavior likely explain our results as well. A sparse graph results in behavior that is more dominated by mismatch and variation rather than coupling, and also results in a more quantized Hamiltonian that exacerbates the effect of an error on the Hamiltonian value.
Notably, for certain problem instances, the DIMPLE solver is capable of producing results with higher quality than the reference algorithm. This indicates that DIMPLE may have promise as a competitive technology to traditional CPU and GPU-based Ising solvers.
Time-to-Solution
We measured time-to-solution for different graphs as well. DIMPLE settled to a steady-state solution within 10us, or 2500 clock cycles of our 250MHz FPGA. Solving similar problems using the host CPU on the AWS F1 EC2 instance with the simulated bifurcation package takes 10ms for low-quality solutions and 80ms for higher-quality solutions; comparatively, DIMPLE offers a 1000-8000X speedup, which is very exciting. However, current implements of DIMPLE are unable to practically realize this speedup due to the overhead of loading coupling weights onto the system then reading the spin results. Also, more optimized GPU solvers would likely outperform our CPU baseline significantly. Hopefully, as DIMPLE improves and we fit additional spins on each FPGA, the speedup offered by the coupled-oscillator technique will start to be compelling even considering the data transfer cost.
In Figure 2, like in our previous test, each dot corresponds to a solution attempt by the DIMPLE solver with a randomized physical-logical spin mapping. Like before, dots with the same color are attempts for the same problem instance, while dots with different colors are attempts for different problem instances.
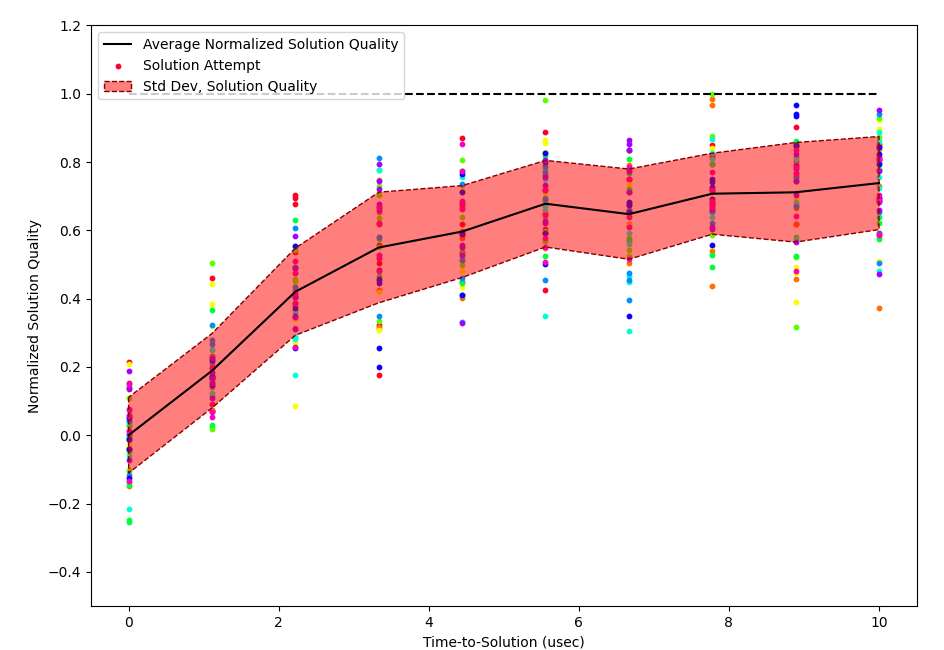
Given that DIMPLE is heavily inspired by Lo et. al.’s all-to-all coupled Ising solver, we’re not surprised to see a convergence time with a similar order of magnitude as their work, in the 10s to 100s of microseconds. It appears that the all-digital coupling method doesn’t have significant negative effects on time-to-solution.
Effect of Noise and Mismatch
We also wanted to understand how different sources of randomness affected the behavior of the DIMPLE solver. Notably, our all-digital method often resulted in the same or similar solutions when one problem was solved multiple times.
Figure 3 shows trials where ten different Ising problems were solved using the DIMPLE solver without randomizing the mapping of physical oscillators to logical spins. We ran the DIMPLE solver ten times for each problem; the solver usually converged to fewer than 10 unique values in those 10 solution attempts. As shown by our earlier results, this is not the case when the physical-logical spin mapping is randomized. This indicates that the dominant source of randomness when solving Ising problems using the DIMPLE solver is transistor mismatch and variation, rather than thermal noise.

Adding external random phase noise might help the solver converge on a more optimal solution by preventing it from getting stuck in local energy minima. Such a feature also may enable new solver capabilities leveraging measurements of the second moment of the converged system under noise, similar to the capabilities described by Aifer et. al. and Böhm et. al.
Adding external phase noise should be easy to do, because the oscillation frequency of the spins is likely not a multiple of the main clock frequency. If we add random phase shifts that update on the rising edge of the main system clock, the phase of the noise will appear random from the perspective of the oscillators, despite the noise source being synchronous. This additional randomness comes from the random relative phase between the oscillation frequency and the system clock. This is a similar principle to ring-oscillator-based true random number generators. The progress of this feature is tracked by Issue #17 on the DIMPLE GitHub repository.
Conclusion
To our knowledge, DIMPLE supports a greater number of all-to-all-coupled spins than any other ring-oscillator-based Ising machine developed to date. It also offers comparable accuracy and time-to-solution as state-of-the-art analog coupled oscillator solvers. DIMPLE is able to achieve this level of performance and scalability using a novel all-digital phase-coupled architecture that can be deployed on large and powerful FPGAs hosted through AWS’s F1 service. Our all-digital phase coupling method also uniquely enables asymmetric coupling, which enables DIMPLE to solve new kinds of asymmetric problems.
This all-digital approach vastly increases the accessibility of the DIMPLE solver. AWS F1 FPGA instances are fairly affordable and scalable, and users can connect from anywhere in the world. Additionally, a fully featured PyTorch frontend helps users unfamiliar with Ising machines develop complex applications in an easy-to-use environment.
We have laid out potential improvements to the DIMPLE architecture. Injecting external noise into the DIMPLE solver may improve solution quality, while also enabling new applications that leverage fluctuations of the solver’s steady-state solution under the presence of noise. We also believe that our support for asymmetric coupling could extend DIMPLE’s capabilities beyond simply solving energy-minimization problems; however, removing asymmetric coupling would reduce LUT utilization and may enable us to fit more spins on each FPGA.
Finally, one major potential performance improvement could come from leveraging Xilinx’s manual routing features. Implementing this will be a lot of work, but may significantly improve system stability and performance.
The phase of the inverse square wave is slightly different from the first square wave, but it turns out this doesn’t actually matter much in practice.
If there are local minima, the solver may get stuck there, but that’s not the case for this specific problem.
Technically, they use transmission gates rather than resistors, so that the design is both compact and programmable. But the principle is the same.
I’m aware this is a vast oversimplification.
The specific value of T1 isn’t important. It’s a function of the physical properties of the NOT gate.
The FPGA programmers among you might notice that this system has no clock! The entire system is based on asynchronous oscillators, which makes it extremely fast. While the clock on a high-end FPGA is limited to hundreds of megahertz, these oscillators are likely running at a frequency of gigahertz if not tens of gigahertz, which is one of the reasons DIMPLE is so fast.