
Making Unconventional Computing Practical
Lessons learned from building weird chips for years.

This blog post is based off a talk that I’ve given a couple times: first at Homebrew, then at Betaworks, and finally at Foresite Labs’ Reinventing the Semiconductor Future Symposium this past week. It’s an interesting topic -- if unconventional computing is really so unconventional, how does it have any chance of becoming practical or mainstream?
Well, unconventional computing is an umbrella term. It can range from the extremely weird, like slime mold computing, to the relatively mainstream, like processing-in-memory. Broadly, unconventional computing refers to all methods of doing computation that differ from the standard Von Neumann architecture, which forms the basis of modern CPUs and, to some degree, GPUs. For decades, the academic community has done research on novel methods of computing, but recently, driven by the end of Moore’s Law transistor scaling and the rising computational demands of AI, some startups and large corporations have been trying to commercialize these unconventional computing technologies.
I’ve worked at some of those startups, and I know the stories of many more. It turns out that taking research ideas, which are designed to maximize novelty and land in impressive journals, and trying to commercialize them is difficult. This blog post, like my talk, is about the lessons learned from trying to move three different unconventional computing ideas out of the lab and into industry.
Processing-in-Memory
When I first encountered processing-in-memory, the dream was simple, but exciting. If we could store data as analog values in a resistive crossbar, we could perform entire vector-matrix multiplications at once. It was incredibly alluring. This sort of architecture would offer incredibly dense data storage, significantly reduce data movement, and take an iterative algorithm and reduce it to a single atomic operation.
There were a couple companies trying to commercialize this sort of architecture. The most well known is Mythic AI, which used flash memory cells as the resistive element in their crossbar. Another startup, Syntiant, proposed doing a similar thing, but was targeting much lower-power applications. Then a large number of research labs were working on using novel resistive memory devices, like resistive RAM (RRAM) and magnetoresistive RAM (MRAM), to implement these crossbars. RRAM and MRAM are a lot less mature than flash memory, but offer increased linearity and density.
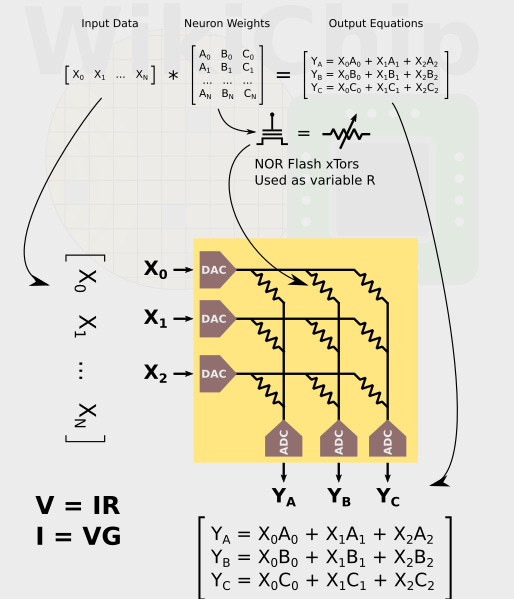
Unfortunately, that original alluring PIM dream is dead. Mythic famously nearly ran out of capital before raising a small down round and replacing their CEO. Syntiant quietly dropped their analog architecture in favor of a conventional digital chip, which has been fairly successful. Many of the research labs working on RRAM and MRAM have struggled to get their chips to scale past simple image classification workloads, owing to device-level mismatch and variability over process, voltage and temperature variations.
“But Zach”, you might object, “haven’t there been successful processing-in-memory companies?” And the answer is actually, yes! My previous startup, Radical Semiconductor, built best-in-class cryptography accelerators using PIM technology. We were acquired by BTQ, where our architecture forms the basis of BTQ’s QCIM offering. d-Matrix is selling fast and efficient LLM accelerators using PIM technology as well. But neither BTQ nor d-Matrix are working on that original analog PIM dream.
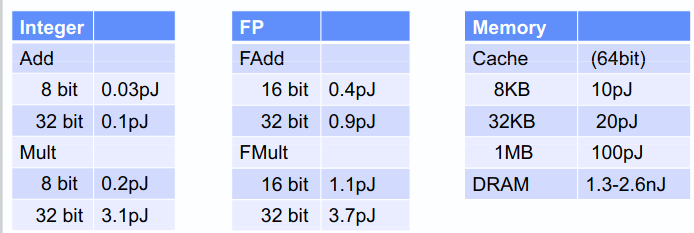
Analog PIM technology offers a number of advantages: reduced data movement, dense storage, and one-shot vector-matrix multiplication. But those advantages are not created equal: just reducing data movement offers a massive performance and efficiency boost on its own. Doing an 8-bit addition operation consumes about 0.3pJ of energy, but fetching data from memory costs upwards of 10pJ. If we develop PIM technology that gives up on multi-level memories and analog one-shot operation, we can still get a 10-100x performance improvement just by reducing data movement.
d-Matrix is developing digital processing-in-memory for matrix-vector operations; by integrating custom digital adder trees directly into SRAM memory arrays, they can still get huge performance advantages. The memory isn’t nearly as dense as the analog arrays proposed by Mythic or the RRAM labs, but they still reduce data movement massively. BTQ’s QCIM focuses on the vector-vector operations at the heart of the number theoretic transform, which powers NIST standard cryptographic algorithms like ML-KEM and ML-DSA.
By narrowly focusing on the biggest advantage PIM offers -- reducing data movement -- and ignoring the secondary benefits of all-analog architectures, startups have built legitimately successful products. And the story is pretty similar for another field that’s traditionally used analog architecture: neuromorphic computing.
Neuromorphic Computing
The original dream of neuromorphic computing, cooked up by Carver Mead in the 1980s, was to build ultra-efficient analog circuits that operated similarly to neurons in the brain. Neurons communicate with electrical pulses, called spikes, that are integrated as charge across the cell membrane of the neuron. The most traditional neuromorphic systems operate the same way, with spikes of voltages integrated onto capacitors inside of silicon neurons. Some neuromorphic systems, like Neurogrid, take this to an extreme, attempting to model all of the complex ion channels in human neurons as accurately as possible using silicon.
But when researchers tried to use these neuromorphic computers to accelerate meaningful machine learning models, they hit a ton of roadblocks. Because neuromorphic architectures use analog circuits, they struggle with temperature changes and manufacturing variability. But also, the spiking neural networks, or SNNs, native to neuromorphic computers aren’t compatible with conventional machine learning techniques. Gradient-based training methods, like backpropagation, don’t support the non-differentiable spiking activations inside of SNNs. This makes commercialization of neuromorphic computing technologies difficult. Customers want hardware that can run the models they already know and love.
There are some successful efforts in the realm of neuromorphic computing, though! But just like d-Matrix and BTQ did for processing-in-memory, they focus on achieving the key advantages of neuromorphic computing in the most practical way. In the case of neuromorphic computing, that advantage is sparsity. Neuromorphic computing systems are so efficient because they operate using sparse trains of spikes, rather than dense vectors of activations. By focusing on sparsity specifically, some companies have been able to build commercially viable neuromorphic-inspired chips.
The team at femtoAI (formerly Femtosense) are building neuromorphic-inspired ultra-power-efficient edge AI processors tailored to sparse networks. However, their chips use digital rather than analog circuits, and operate on sparse conventional neural networks, rather than the esoteric and unwieldy SNNs used by more traditional neuromorphic systems. Their focus on the most impactful benefit of neuromorphic computing ultimately allowed them to get meaningful commercial traction in the smart home and hearing aid markets.
Thermodynamic / Probabilistic Computing
Last but not least is thermodynamic and probabilistic computing, two related fields both focusing on leveraging specialized architectures to accelerate stochastic differential equations (SDEs) and stochastic random sampling workloads. I ran the silicon team at Normal Computing for a year, and before that worked on DIMPLE, the largest open-source fully-connected Ising machine ever demonstrated -- so I know the space pretty intimately.
The story of thermodynamic and probabilistic computing starts off similarly to that of processing-in-memory and neuromorphic computing: a big dream and a lot of cool ideas for new circuits and new materials. Supriyo Datta’s group at Purdue proposed building probabilistic bits (p-bits) using stochastic magnetic tunnel junctions, which required new materials and fab processes. Normal Computing proposed analog circuits with thermal noise to act as unit cells that could be coupled together. And Extropic proposed superconducting circuits to implement their p-bits. All of these were exciting ideas. None were particularly practical.
Currently, the largest published result demonstrating a p-bit system comes from Karem Camsari’s lab. They don’t use magnetic tunnel junctions or analog circuits. Instead, they use a digital random number generator to generate noise, and digital logic to implement couplings between p-bits. Normal Computing is also leveraging a digital architecture to accelerate the SDEs at the heart of diffusion models. And Extropic has ditched their esoteric superconductors in favor of mixed-signal CMOS circuits.
It took a little while, but so far, it’s seemed like the innovators in the world of thermodynamic computing have learned the lessons from other kinds of unconventional computing. Often, analog circuits are expensive and difficult to implement, even though they may be elegant and exciting. Digital architectures are reliable, efficient, and easy to manufacture and sell at scale. And so when unconventional computing technologies move from academic labs into industry, which cares less about publishing novel papers and more about selling chips, scalable digital architectures designed to maximize the key benefits of a new technology, while avoiding its biggest downsides, often win out.
Great write up! Are you familiar with any of Jennifer hasler’s work at gatech? You seem to have a very skeptical view of fully analog networks but I’m from that lab and we’ve shown programmable analog cells as well as dense single fet multipliers all the way from 350nm down to 16nm FinFet. Its using floating gates and goes against the claim that rram or other struggling emerging memories would produce better density. Additionally we avoid the data converter trap of losing efficiency at the edge. We also tapeout our chips not relying on sims!
I can post links to all of these and papers on our custom tooling + demonstrated applications if you’re curious.
one of my professors who works on neuromorphic computing says that the only place where it will make
sense is when you’re processing analog signals - edge computing for neural acquisition systems for example. thoughts?