
Update: Post-Quantum Cryptography is definitely not broken.
Plus, a cool way to think about parallelism.

Two weeks ago, I wrote a blog post about a new quantum algorithm that purported to crack the Learning with Errors (LWE) problem. At the time, the approach seemed promising, but wasn’t powerful enough to compromise real-world post-quantum algorithms based on LWE. Well, there’s even better news now for those of us working on post-quantum cryptography: a key error has been identified in the algorithm, so it can’t solve LWE after all. Let’s dive a bit deeper into how it works.
Reducing the LWE problem
As we discussed last time, an instance of the LWE problem consists of a random matrix A, a secret vector s, and a large integer q. We also draw an “error vector” e from a random small distribution; we usually use a Gaussian distribution or something similar. Using those values, we can calculate a vector b:
If an adversary is only given A and b, it’s very hard to calculate the value of s. From this property, we can build up really useful and interesting cryptography schemes. Intuitively, LWE instances with larger error vectors are harder to solve, while problems with smaller error vectors are easier.
Chen’s paper starts with a couple important reductions from the LWE problem to problems that might seem easier to attack. First, he sets the first k coordinates of the error vector to 0. Then he provides a proof that, as long a k is smaller than the dimension of the secret s, this problem is still as hard as LWE. Similarly, if the first k coordinates of the error vector are arbitrary values chosen by the attacker, rather than 0, the problem is still as hard as LWE!
By applying this trick, and then another reduction that transforms the secret distribution to follow the error distribution, Chen ends up with an instance of LWE where the attacker gets to choose k elements of the secret vector. As long as k is small enough, this is still just as hard to crack as standard LWE.
To understand why this works intuitively, imagine that the A matrix is 256 rows tall and 512 columns wide. In this situation, the s vector is 512 elements long. If we split the A matrix vertically into two chunks, we can build two LWE “subproblems”. We put the “chosen” s coefficients into the first subproblem, and the “hidden” s coefficients into the second. By doing this, we preserve a 256x256 LWE subproblem that’s still computationally hard.
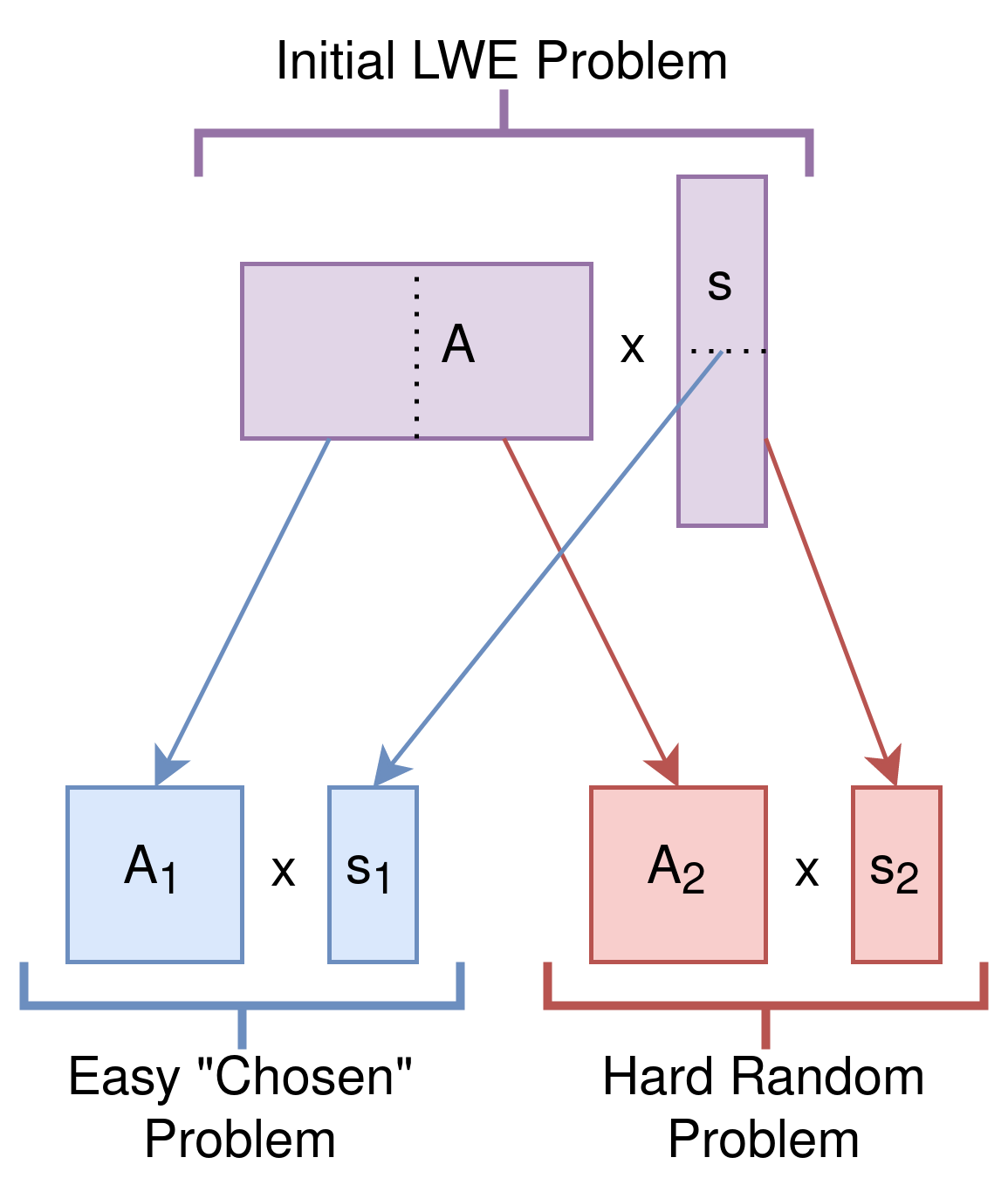
This is a vast oversimplification, but should hopefully provide intuition for the transformations Chen is doing here. This special instance of LWE, with k chosen elements in the secret, is the starting point for his proposed algorithm, and even though this specific algorithm failed to solve LWE, these techniques will likely continue to be leveraged by future researchers -- so it’s useful to understand them!
Polynomial time quantum algorithms for LWE
Next, Chen takes his special k-chosen-parameters LWE instance and starts putting it through a quantum algorithm. Specifically, he runs a number of quantum fourier transforms (QFTs); the output of each set of QFTs is a linear equation that’s related to the LWE secret and error vectors. If we run this set of transforms many times, we get a system of linear equations. Then, finding the LWE secret is as simple as solving a system of linear equations!
So, what’s the catch? Well, in Step 8 of the algorithm, Chen constructs a quantum state he labels |φ8.g〉. This quantum state is supposed to leverage the “chosen” values in the secret vector to help create the linear equation he’ll ultimately use to find the LWE secret. However, the way this state is constructed contains a bug. The specifics of the bug are a bit nuanced, but intuitively, this means this algorithm is unable to use the “chosen” secret values to actually help extract the “hidden” secret values.
With that bug found, how much promise does this paper still have? Well, Chen himself has stated that he doesn’t know how to fix the bug, and instead plans to leave the paper as-is to help inspire future research. For post-quantum cryptographers, this is great news: every time somebody tries to break LWE and fails, we can feel a little safer about the algorithms we’re working to deploy worldwide over the next few years. And for the quantum algorithms researchers, even though Chen’s paper wasn’t fully correct, he’s pioneered a bunch of interesting techniques here. The tactic of leveraging the “chosen k” LWE variant is really interesting, and opens up many exciting avenues for future research!
I’ve also been thinking about new ways to frame key concepts used in chip design, so I put together a short piece on one of the most important computer architecture concepts out there: parallelism!
A Different Way to think about Parallelism
One of the first things you learn in a computer architecture class is that there are two main ways to improve hardware performance: parallelism, and pipelining. Generally, parallelism is presented as a way to make a workload run faster, at the cost of additional hardware. Below, we add a second 4-bit adder to a system. This doubles its additions-per-cycle, but also doubles the hardware cost.
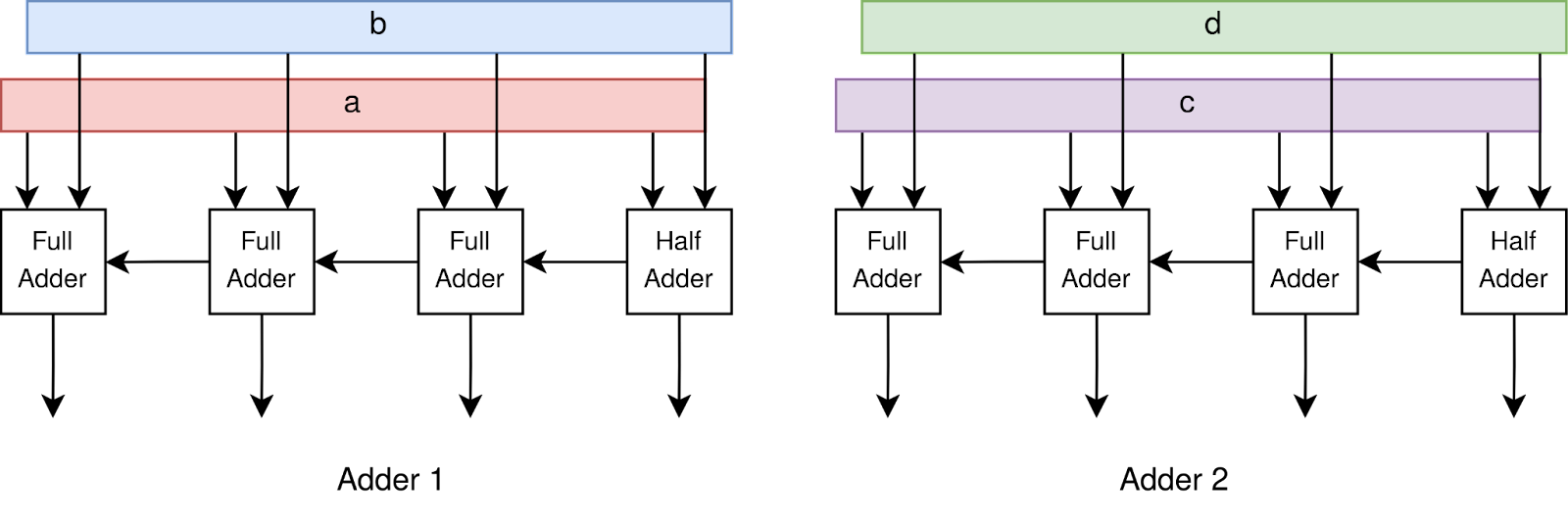
I think this classical presentation of parallelism misses a key efficiency advantage. This time, let’s keep our hardware resources fixed, but switch from one 4-bit adder to 4 1-bit adders. With those 4 1-bit adders, we can perform four different 4-bit additions at once, using bit-serial processing.

Both of these designs require 4 adder cells, and can perform four 4-bit additions in 4 cycles; it seems like the two systems should have equal performance. But the parallel system has a hidden advantage: it can run at a faster clock frequency.
In our 4-bit-adder system, the far right input bit needs to flow through all four adders before it can finally reach the far left output bit. Because each adder has a tiny delay associated with evaluating its inputs, the 4-bit design has a minimum clock period of 4 x adder_delay. However, in our parallel system, the longest data path flows through a single adder. Its minimum clock period is only adder_delay.

So with the same number of adders, our parallel implementation can run four times faster! However, this performance improvement only matters if we’re able to actually do four different 4-bit additions at once. That’s why bit-serial implementations like this are usually reserved for digital signal processing or certain AI chip architectures, where massive parallelism is common.
Nice post. The 4 parallel 1-bit adder example reminds me of SIMD