
Apple’s M-series CPUs just got hacked.
Speculative execution strikes again.

Apple’s M-series chips have been a massive success for the company. By integrating a number of features to enhance performance and efficiency, Apple’s ARM-based chips have been able to significantly outperform x86-based laptop CPUs developed by Intel and AMD, while also consuming less power. But, as the industry has learned time and time again, features that increase performance often have the side effect of decreasing security.
As it turns out, the M-series CPUs are no different. Recently, a team of researchers from Georgia Tech and Ruhr University Bochum identified a pair of vulnerabilities, called SLAP and FLOP, in Apple M2 and M3 CPUs. They take advantage of new kinds of speculative execution that Apple introduced to increase performance: the Load Access Predictor, and the Load Value Predictor.
Like it did in the classic Spectre and Meltdown vulnerabilities, speculative execution often leads to security flaws in CPUs. Today, we’re going to dive into how exactly SLAP and FLOP work, and how they relate to the fundamental tradeoff between performance and security in modern high-performance processors.
SLAP and the Load Access Predictor
Conventionally, speculative execution is a technique where a CPU guesses which instructions come next in an instruction stream to increase performance. Modern CPUs are pipelined: instead of executing one instruction at a time, each instruction passes through multiple different stages that each handle a small part of the execution.
This can significantly boost system performance by increasing the clock rate a CPU is able to run at. However, there are some major challenges: what if you need to execute an if statement, or some other kind of branching control logic? You don’t know which way you need to branch until the instruction that corresponds to the if statement gets to the Execute (EX) stage of the pipeline -- but at that point, you’ve already needed to fetch additional instructions to keep your pipeline running at full speed. So what should you do? Well, you could insert a “bubble” in your pipeline, but this slows down your CPU.

Modern CPUs solve this problem using speculative execution. When a CPU sees branching control logic, it guesses which instructions should be executed next, using a module called a “branch predictor”. If it turns out the CPU guessed wrong, it has to “flush” the pipeline and fetch the correct instructions, resulting in performance degradation. But if the branch predictor is very accurate, it can significantly improve CPU performance.
The big security flaw comes in when speculative execution is performed on code that’s supposed to be secure. Certain instructions, when speculatively executing on an incorrectly predicted branch, can cause side effects on the processor’s state that don’t get removed when the CPU flushes the pipeline. A key example is the state of the system’s cache. By observing the side effects, an unprivileged attacker can read secure data. A more in-depth example is given in the original Spectre paper.
SLAP is a little bit different. It exploits a feature on Apple’s M2 and later CPUs called the Load Access Predictor, or LAP. The LAP is a speculation unit that specifically tries to guess which memory address and instruction will access, before the true value of that memory address has been computed.
For example, let’s say we’re running the instruction ldr x0, [x1] to load the register x0 with the data stored at the address corresponding to the value stored in the register x1. We can’t actually perform this load until we’ve calculated the value that’s supposed to be stored in x1 -- but if we want to have a deeply pipelined processor, we may not know that value by the time we want to execute the load instruction. What the LAP does is predict what value would be in x1. As shown in Figure 1 from the SLAP paper, if x1 follows the sequence 0x10, 0x20, 0x30, a reasonable next prediction is 0x40.

If an attacker sets up this sort of strided data access pattern using double pointers, they can cause the program to speculatively execute code that references arbitrary addresses, including addresses containing secret data. This can cause the same sort of cache side-effects as Spectre, from which the attacker can reconstruct the secret data.

The LAP can even be used to divert program control flow and speculative execution functions that shouldn’t be executed. This makes it incredibly powerful as an attack vector. The researchers go on to prove how powerful SLAP is by using it to read data across websites; essentially, a malicious website can get access to data entered on other webpages open in the same browser.

If you’re interested in diving deeper, I’d really recommend reading the SLAP paper yourself -- it’s fascinating. In the meantime, though, it’s time we talk about FLOP, SLAP’s sister vulnerability. And get ready, because as scary as SLAP seems, FLOP is even worse.
FLOP and the Load Value Predictor
FLOP exploits a similar, but slightly different, Apple M-series processor feature: the Load Value Predictor, or LVP. First introduced on the M3 chip, the LVP observes data being loaded from memory. If reading the same address returns the same data repeatedly, the LVP allows the processor to assume that future loads from that address will continue to return that same data. This means that the processor will speculatively execute instructions as if it had loaded that data. Then, when the data is actually loaded, if it doesn’t match what was predicted, the processor flushes its pipeline and rolls back to before the speculation began.
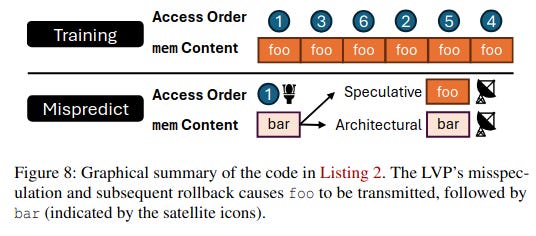
This behavior is shown in Figure 8 from the FLOP paper. First, the LVP is trained such that it assumes foo will be read from mem. Then, once mem is changed to bar, the processor first speculatively executes code assuming mem was foo before rolling back, flushing, and executing code properly with mem read as bar.
Like SLAP, FLOP starts becoming dangerous when we start introducing indirection -- that is, we use pointers that get speculatively fetched and affect processor execution. For example, the researchers first repeatedly access an array of pointers, aop, at an index foo. They train the LVP to assume that the index will always be foo; then, when they change the contents of the array so that the pointer at index foo points to secret data, the processor accesses that secret data and produces side effects that the researchers can observe.

A similar technique can be used not just to access secret data, but to call secret functions, as shown in Figure 13 from the FLOP paper.

This is a very powerful attack; on the FLOP website, the researchers have a video of an attack where a webpage can open and read a user’s email client by manipulating the LVP.
Ultimately, Apple silicon is so powerful and efficient because their CPU architects put in architectural optimizations like the LAP and LVP. But these sorts of optimizations inherently introduce security vulnerabilities: if you’re ever guessing at what values instructions and memory might take, there’s always a chance you make a guess that makes your system insecure. This is the big challenge of designing systems that are both high-performance and secure. I wish I could suggest a simple solution, but ultimately, designing any chip will be a compromise between performance and security that depends on the needs of the specific system that the chip will slot into.
Great post thanks! Do we know how much performance would be lost by "turning off" the LVP and LAP? I would naively guess these LVP and LAP would not be very helpful in deep neural net training or inference then, is this wrong?